
I have an LED Sign in my office that displays information like the weather, currently playing music, and other stuff. One day I added a random movie quote to the rotating text just for fun. A few days later I swapped it out for another one. As you can imagine, an idea hit. What if I could randomly add a new quote every few days? There must be a web service to pull quotes from, right?
Hence began my search for an existing service to pull movie and TV show quotes from. I found a few options, but I came up short of what I wanted. Many sites cataloged movies, but not quotes. Others had quotes but no method to pull them programmatically. The IMDB in particular looked the best but their “quotes” were often several lines of dialog from the film. Plus I just didn’t want to mess around with integrating with them since it’s a proprietary site.
At this point I figured I could either a) drop this idea or b) try and build something. Something as simple as text file with a bunch of favorite quotes in it would have worked but I didn’t want to have to generate all the content myself. I thought it might be fun to build something my friends and family could add quotes to as well. It would have the added bonus of making the quotes more diverse than just things I thought up.
Table of Contents
Scoping the Problem
Breaking this down I now had two distinct goals. The first was creating a simple website to capture quotes. This should be something people could quickly use from their phones. The other was a backend to pull out the quotes with some basic search parameters. As far as collecting the quotes I didn’t want to get too bogged down in metadata but some type of organization would be needed. Basic fields for a movie would be:
- Movie Name
- Character speaking
- Quote
For a TV show it would be the same with the addition of a field for the episode. Most of these quotes would be pulled from memory so I didn’t want to make it a homework assignment. For the backend API I wanted the ability search or filter on the following:
- Movie, TV show, or both
- Random or specific title
- Max number of characters
The last value was particularly important to me. Some quotes can get really long and I wanted to filter them based on where they would display. For something like an LED sign a whole paragraph of text can’t be shown easily. I figured this would be easily done with something like the char_length function.
The Backend
The Database
For the database I decided to use MariaDB. I went back and forth a bit on if I needed an actual database or something file based like SQLite. In the end I wasn’t sure how many quotes I’d be collecting and didn’t want the flat file to be a bottleneck if it got too large. Plus I have a local MariaDB instance running on my home lab so spinning one up wasn’t really an issue. I threw together a quick database model and created the schema for use.
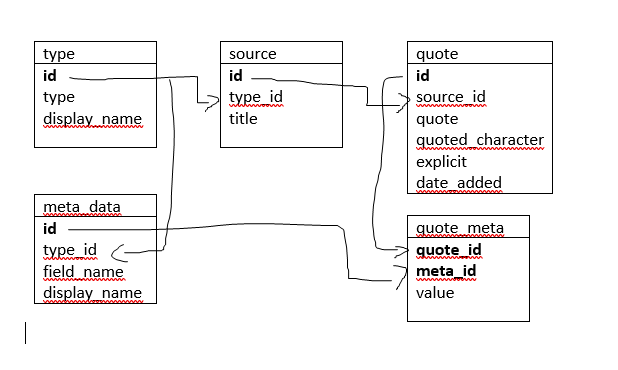
This isn’t the best schema I’ve ever come up with but it looked like it would do the job. Each source would either be a Movie or a TV show. Sources could contain many quotes. I did add some meta data tables to make sure I could collect more data over time easily if I wanted. I also added the explicit boolean field for each quote. I thought this could be a search field or API parameter to limit results you didn’t want tossed up where the kids might see them. More on that later.
Web Framework
With the database done I thought about what framework I’d want to use. Normally I’d jump in to some kind of MVC framework but I wanted to try something I hadn’t done before. I decided on the Slim Framework. This is a simple PHP framework that lets you define routes (like /api/random) which get a Request and Response object to code your logic. It also integrates with a template engine that would make generating HTML content pretty easy. A little digging on their website showed it would integrate with a database so I jumped in. On the PHP side a request comes in based on a route.
// return HTML page
$app->get('/', function (Request $request, Response $response, $args) {
$view = Twig::fromRequest($request);
$view_params = ['page_title'=>'My Page'];
return $view->render($response, 'index.html', $view_params);
})->setName('index');
// return JSON results
$app->get('/api/random', function (Request $request, Response $response, $args) {
$quote = ['quote'=>'movie quote', 'source'=>'movie title'];.
$response->getBody()->write(json_encode($quote));
return $response->withHeader('Content-Type', 'application/json');
})
On the HTML side you create a regular HTML page but it can include templated variables where you want things to load dynamically from your PHP backend code. This was familar to me from using Jinja as part of my Trash Panda project.
<html>
<head>
<title>{{ page_title }}</title>
</head>
<body>
<!-- content here -->
</body>
</html>
You can get more complicated by loading in database classes or injecting session information with each route as well. Using this framework my idea was be to have a simple web front end that would allow users to add and view quotes already submitted. The front end would pull data from a backend REST API that could be used directly to integrate with other things (like my LED sign).
Collecting Quotes
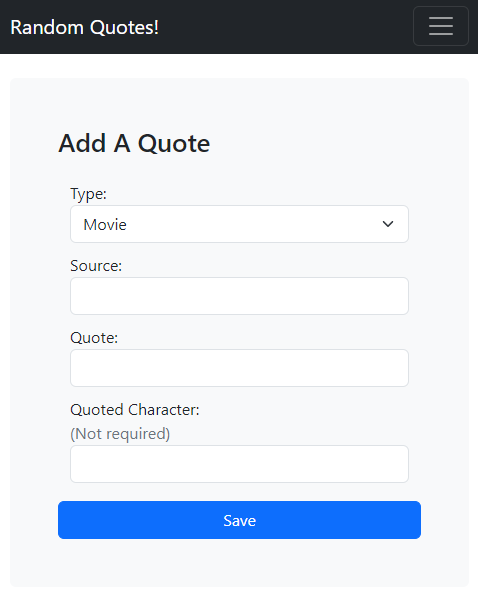
Creating a default page and loading some quotes proved to be pretty easy (thanks Bootstrap!). Within a few hours I had a pretty decent looking landing page and some API methods like /api/random to pull in quotes from the database. I threw together an Add Quote form with a couple of simple fields.
Data Hygiene
While it all worked I quickly saw a few issues. The first of which was simple data hygiene. How to make sure that the sources for quotes were entered uniformly and how to avoid duplicate quotes? To solve the source problem I added a backend method /search/title/{type} that would return all source titles for the given type (movie or tv). This works by utilizing an SQL query using the LIKE syntax.
select source.title from source inner join type on source.type_id = type.id where type.type = 'movie' and source.title LIKE 'Aveng%';
It allows for queries like /search/title/movie?q=Aveng to search for any existing source title that includes Aveng in the title like Avengers or Avengers:Age of Ultron. This provides a list I can display with some javascript on the web frontend. As the user types this list updates with a selection of existing titles. Basically a type of Autocomplete.
To solve the other issue I needed a way to determine if a quote was too similar to an existing quote before adding it to the database. PHP provides a function called similar_text to compare two text strings. Within the Add Quote logic I added a check to pull in all quotes for the given source and compare them against the proposed new quote.
// check quote against existing, probably duplicate if over percent threshold
function duplicate_check($quote, $existing_quotes, $threshold_percent=75){
$result = ['is_dup'=>False];
$count = 0;
// walk through each quote, or quit if duplicate found
while(!$result['is_dup'] && $count < count($existing_quotes))
{
// similar text puts percent into arg variable
similar_text($quote, $existing_quotes[$count]['quote'], $percent_similar);
if($percent_similar >= $threshold_percent)
{
$result['is_dup'] = True;
$result['id'] = $existing_quotes[$count]['id'];
}
$count ++;
}
return $result;
}
The similar_text function is a little weird in that the percent isn’t assigned but passed in by reference. You use it as an argument and then reference it after. The returned map contains a simple yes/no value and the id of the matching quote. If a new quote exceeds the matching threshold the user is told it exists already, with a link to the existing quote.
Explicit Language Check
In order for the explicit language check to work I’d have to check the quote prior to adding it to the database and set the explicit field accordingly. After a little GitHub searching I found this PHP class where someone had already done the work of cataloging profanities (like 1,200 of them) and writing a testing mechanism. Unfortunately it didn’t seem to be available directly via Composer so I had to bootstap it in myself. If you’ve never done this before you simply create another directory outside your main source directory of the project, I called my custom/. Within this directory create any structures you need to organize the third party libraries. I ended up with the following:
custom/
DeveloperDino/
ProfanityFilter/
ProfanityCheck.php
src/
composer.json
After this simply add an autoload directive to your composer.json file and run composer update. This will create the stubs needed to autoload class files from your custom directory, the same as it does from the vendor directory. In my example below they’ll all start within the App namespace. Imports would look like use App\DeveloperDino\ProfanityFilter\ProfanityCheck
"autoload": {
"psr-4": {
"App\\": "custom/"
}
}
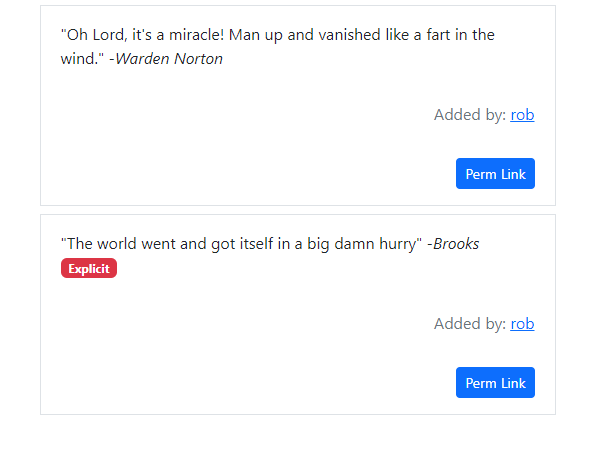
Once everything was linked up doing the profanity check was fairly easy. On the web interface side I added badges that said explicit as well as made this a search filter using ?explicit=false as part of the query string.
// hasProfanity() returns boolean value
$explicit_checker = new ProfanityCheck();
$explicit_checker->hasProfanity($data['quote'])
Gamification
By now I had all the pieces working. Adding a few other bells and whistles like quote permalinks to pull up specific quotes helped round out the web frontend. As I thought more about collecting quotes I realized I needed some kind of incentive to get others to participate. The idea of a Leaderboard to turn the whole thing into a game was appealing.
To do this I’d have to keep track of who added each quote as well. By now I was getting a bit lazy so rather than implement a whole user system I simply added an added_by field to the database. This was a simple text field set at the time the quote was created. I also threw together a quick landing page to enter your username prior to adding any quotes so this could set an HTTP Session variable. I found out here that Slim doesn’t have built in Session support beyond PHP’s built in variables. I did find a decent plugin though bryanjhv/slim-session though. This method runs risk of other people using someone’s username but I figured this is for home use so I could expect people to play nice. To make this more “commercial” you’d want to add a real profile system with a login password for sure.
Once the username piece was working I coded a quick leaderboard page. This gave some simple stats to show who was adding the most quotes and how many different sources they were adding to. The SQL for this is:
# select total quotes and unique sources, grouped by user
select count(id) as total_quotes, count(distinct source_id) as total_sources, user from quote group by user order by total_quotes;
As an added bonus this also allowed me to add additional frontend pages for seeing all quotes by a specific user. Logged in users could also edit their quotes just in case of mistakes.
Rolling It Out
Looking back at my initial idea of collecting movie quotes I think it’s safe to say this project got away from me. I’ll admit it’s hard to resist the urge to add more and more polish to a project, even if it’s just for my own use. I rolled it out to my friend/family circle and have started to get some quotes coming in. In just the first weekend I got over 100! Using the REST API I’ve started pulling a new quote for my LED sign each day. Lots of dev time for a pretty simple idea but it was a fun project and well worth the effort. I’m glad I took the time to learn a bit about the Slim Framework and it was nice to play with PHP again as well.